
Introduction
In 2017, a groundbreaking paper titled “Attention Is All You Need” by Vaswani et al. introduced the Transformer, a deep learning architecture that has since revolutionized natural language processing (NLP) and beyond. This model eliminated the need for recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), leveraging only self-attention mechanisms to process data more efficiently.
In this blog post, we’ll break down the key ideas of the paper, explore the Transformer’s architecture, and discuss its impact on AI.
The Problem with Traditional Models
Before the Transformer, NLP tasks relied heavily on RNNs and LSTMs. While effective, these models had key limitations:
- Sequential Processing: RNNs process words one by one, making training slow and limiting parallelization.
- Long-Term Dependencies: They struggle to retain information over long sequences.
- Vanishing Gradient Problem: Gradients diminish over time, making training inefficient.
To address these issues, Vaswani et al. proposed a completely new approach using self-attention.
The Transformer: A Paradigm Shift
The Transformer introduced a novel deep learning architecture based entirely on self-attention mechanisms, eliminating the need for recurrence. It consists of two main components:
- Encoder: Processes the input text and generates contextual representations.
- Decoder: Uses these representations to generate the output sequence.
The architecture consists of stacked identical layers, each containing:
- Multi-Head Self-Attention: Captures relationships between all words in a sequence simultaneously.
- Feed-Forward Networks: Applies transformations to each token.
- Layer Normalization & Residual Connections: Helps with stable training and gradient flow.
Understanding Self-Attention
The core idea behind the Transformer is self-attention, which allows the model to focus on relevant words regardless of their distance in the sequence. Here’s how it works:
- Each word (token) in the input sequence is represented as a vector.
- The model computes three values for each word:
- Query (Q)
- Key (K)
- Value (V)
- The attention scores are calculated using the formula:
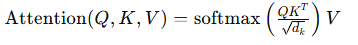
This allows the model to determine which words are most important for understanding context.
Why the Transformer Is Revolutionary
- Parallelization: Unlike RNNs, Transformers process all tokens simultaneously, leading to faster training.
- Better Context Understanding: Captures long-range dependencies more effectively.
- Scalability: Has led to massive language models like BERT, GPT, and T5, which power today’s AI applications.
Real-World Impact
The Transformer has changed AI across various domains:
- NLP: Powers Google Search (BERT), OpenAI’s ChatGPT, and more.
- Computer Vision: Used in Vision Transformers (ViTs) for image analysis.
- Protein Folding: Helps in biological research, such as DeepMind’s AlphaFold.
Conclusion
The paper “Attention Is All You Need” laid the foundation for modern AI advancements. By eliminating recurrence and leveraging self-attention, the Transformer has enabled faster, more powerful, and more scalable AI models.
As AI continues to evolve, the principles introduced in this paper will remain at the core of future innovations.
Reference
Attention Is all You Need (1706.03762)