Retrieval-Augmented Generation (RAG) techniques have emerged as a pivotal advancement in enhancing large language models (LLMs), enabling them to access up-to-date information, reduce hallucinations, and improve response quality, especially in specialized domains. A recent study titled “Searching for Best Practices in Retrieval-Augmented Generation” delves into optimizing RAG workflows to balance performance and efficiency.
Understanding the RAG Workflow
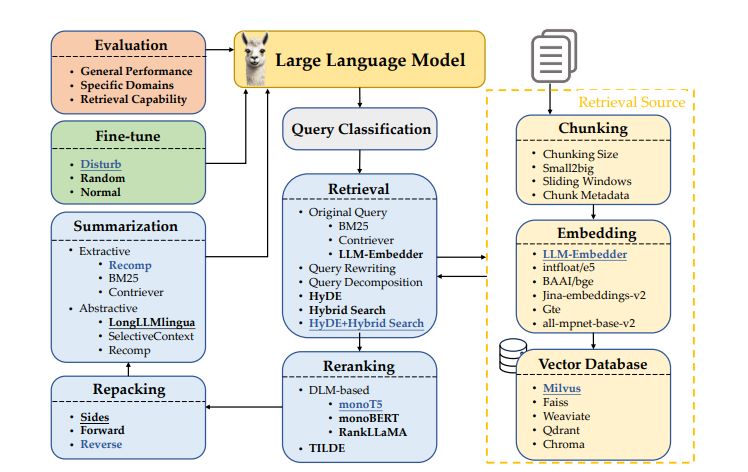
A typical RAG system integrates multiple components:
- Query Classification: Determines if retrieval is necessary for a given input.
- Retrieval: Fetches relevant documents based on the query.
- Reranking: Refines the order of retrieved documents to prioritize relevance.
- Repacking: Structures the retrieved documents for optimal generation.
- Summarization: Extracts key information, eliminating redundancies to aid in response generation.
Each component offers various implementation methods, influencing the system’s overall effectiveness and efficiency.
Key Findings from the Study
The researchers conducted extensive experiments to identify optimal practices within each RAG component:
- Query Classification: Implementing a query classification step can enhance efficiency by determining when retrieval is necessary, thereby reducing unnecessary processing.
- Retrieval Methods: Combining traditional lexical search methods like BM25 with neural retrieval models such as Contriever yielded superior results, leveraging the strengths of both approaches.
- Reranking Techniques: Employing reranking models like monoT5 and RankLLaMA improved the relevance of retrieved documents, leading to more accurate responses.
- Chunking Strategies: Optimal document chunking, considering size and overlap, was crucial for effective retrieval and generation, ensuring that relevant information is neither missed nor redundantly processed.
- Embedding Choices: Utilizing embeddings from models like intfloat/e5 and BAAI/bge enhanced the semantic representation of documents, facilitating better retrieval and generation outcomes.
- Summarization Approaches: Integrating summarization techniques, both extractive and abstractive, helped in distilling essential information, improving the coherence and relevance of generated responses.
Advancements in Multimodal Retrieval
Beyond text-based retrieval, the study explored multimodal retrieval techniques, demonstrating significant enhancements in question-answering capabilities involving visual inputs. By employing a “retrieval as generation” strategy, the system could generate multimodal content more efficiently, broadening the applicability of RAG systems.
Implications and Future Directions
The findings from this study provide valuable insights into constructing efficient and effective RAG systems. By meticulously selecting and optimizing each component, developers can build systems that deliver accurate and timely information, tailored to specific domains and user needs. Future research may focus on further refining these components and exploring new modalities to enhance the versatility and robustness of RAG systems.
For those interested in implementing these best practices, resources and code are available at the study’s GitHub repository:
References
Searching for Best Practices in Retrieval-Augmented
Generation 2407.01219