Text embeddings have become a cornerstone in natural language processing (NLP), enabling machines to understand and process human language effectively. With the advent of large language models (LLMs) and applications like retrieval-augmented systems, the demand for high-quality, universal text embeddings has surged. A recent comprehensive review by Hongliu Cao delves into the advancements in universal text embedding models, particularly those excelling in the Massive Text Embedding Benchmark (MTEB).
Evolution of Text Embeddings
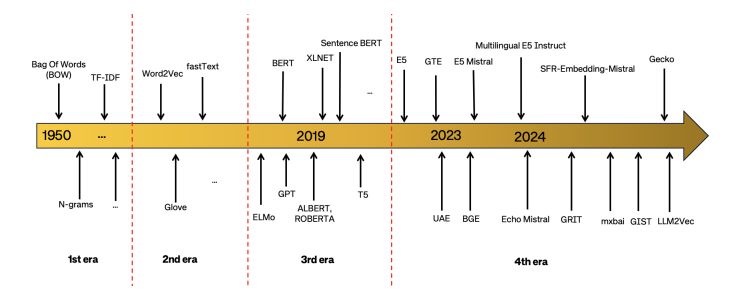
The journey of text embeddings can be segmented into three distinct eras:
- Count-based Embeddings: Early methods like Bag of Words and Term Frequency-Inverse Document Frequency (TF-IDF) represented text by counting word occurrences, lacking contextual understanding.
- Static Dense Word Embeddings: Techniques such as Word2Vec, GloVe, and FastText introduced dense vector representations, capturing semantic relationships but assigning a single vector per word, irrespective of context.
- Contextualized Embeddings: The latest phase employs models like BERT and GPT, generating dynamic embeddings that adapt based on context, offering a more nuanced understanding of language.
Recent Advancements in Universal Text Embeddings
Recent progress in universal text embeddings is attributed to several key factors:
- Enhanced Training Data: The availability of larger, more diverse, and higher-quality datasets has enriched model training, enabling embeddings to generalize across various tasks and domains.
- Synthetic Data Generation: Leveraging LLMs to create synthetic data has supplemented training resources, especially in scenarios with limited labeled data.
- LLMs as Backbones: Utilizing large language models as foundational architectures has led to the development of more robust and versatile embedding models.
Performance on the MTEB Benchmark
The Massive Text Embedding Benchmark (MTEB) serves as a comprehensive platform to evaluate embedding models across diverse tasks. Models that have incorporated the aforementioned advancements have demonstrated superior performance on MTEB, showcasing their ability to handle a wide array of NLP challenges effectively.
Challenges and Future Directions
Despite significant progress, certain challenges persist:
- Generalization Across Domains: Ensuring embeddings maintain performance across varied and unseen domains remains an ongoing endeavor.
- Computational Efficiency: Balancing the complexity of models with computational resources is crucial for practical applications.
Future research directions proposed include developing more efficient models, exploring unsupervised learning techniques, and enhancing the interpretability of embeddings.
In conclusion, the field of text embeddings has witnessed remarkable advancements, with universal models playing a pivotal role in modern NLP applications. Continued research and innovation are essential to address existing challenges and fully harness the potential of these embeddings in diverse real-world scenarios.
Reference
Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark 2406.01607